Quest to diffusion [log mode]
but claude said i need to do auto/ variational encoder, U-NET before diffusion.
Auto encoder
little cramp up and down ride through latent space.
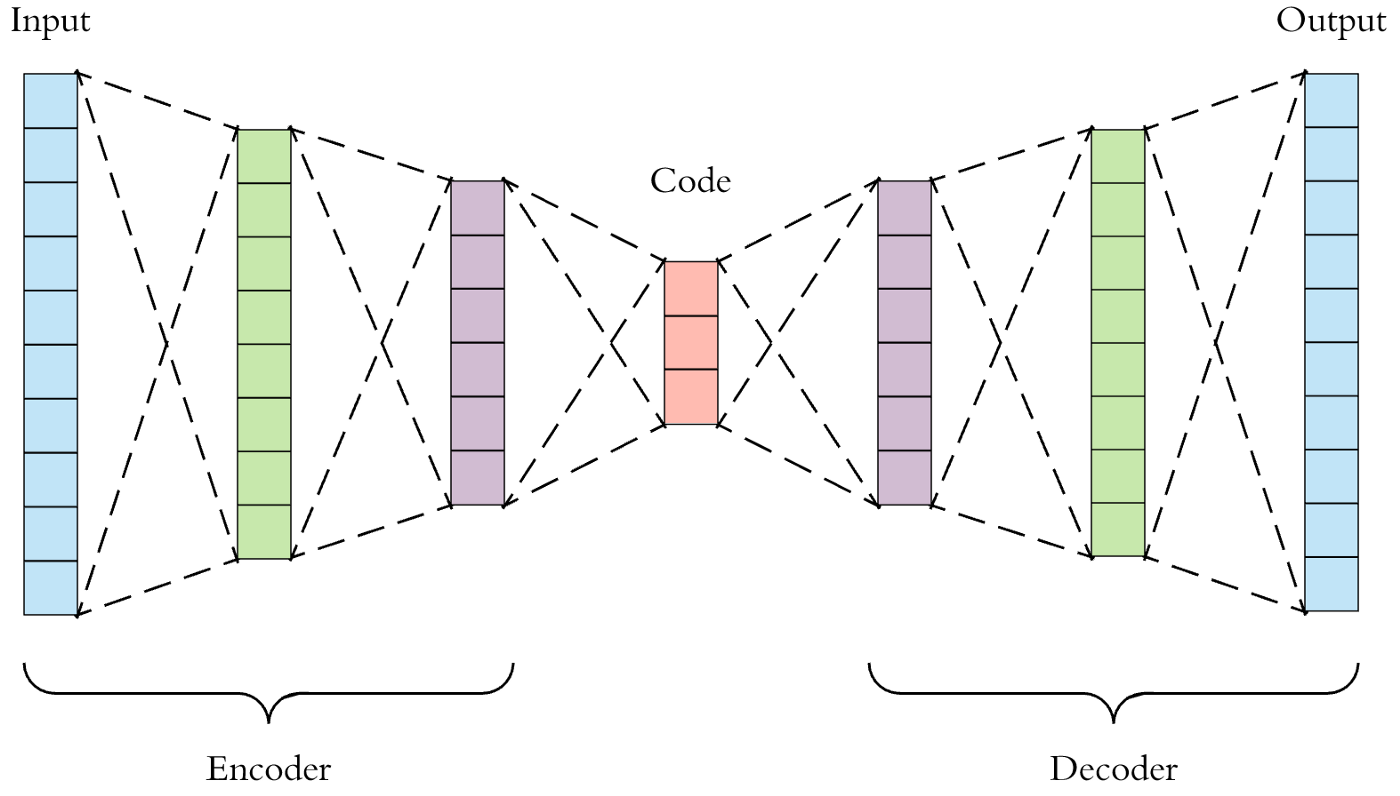
completed so far,
e.g code Sample auto-encoder:
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(True),
nn.Linear(128, 64),
nn.ReLU(True),
nn.Linear(64, 12),
nn.ReLU(True),
nn.Linear(12, 3) # bottleneck
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(True),
nn.Linear(12, 64),
nn.ReLU(True),
nn.Linear(64, 128),
nn.ReLU(True),
nn.Linear(128, 28*28),
nn.Sigmoid() # depends on the reconstruction output dist. mostly normalized/ standardized
)
> be Auto Encoders
> stack linear/ conv2D layers with non-linearity in btwn.
> encoder wojak mogs you step by step to lower representation untill u bottle down.
> decoder takes encoder's bottled brain to spawn you back to big chungus, struct is identical to encoder blocks.
> uncanny but close to earlier shit. backprob on reconstruction L.
> yea yea learned latent space is meh, reconstruction is poor. VAE makes it better by making latent dist to follow gaussian.
> works like PCA but better, scalable, simpler with NN.
other things:
> for better understanding, check code gaussian.
> final encoder layer w/o bias and activation to make latent space free-flow. final decoder layer sigmoid/ tanh to reconstruct the values back.
looks simple as far as i checked. might add nuances later. sye fn.
VAE

> so, although auto-encoder works, generating new samples from decoder is difficult with it.
> because the input to decoder is "some output" from the encoder which doesn't have any known form. we can't generate any random values and pass it to decoder and it generates new points. also learnt latent dim space in AE is also may not be continuous. [insert image here later to explain this]
> it is important to formulate the input to decoder in a certain form (known distribution) so we can sample from it and actually generate synthetic data.
> make it gaussian and re-parameterization trick
[WIP, contemplating]
ELBO
> as already mentioned, in VAE we model the latent space to follow a certain distribution (Gaussian here), so that we can sample any arbitrary point from this distribution and the decoder can "just work" with this to make our life simpler.
> since we go from input dim -> latent dim -> reconstruction, ELBO is a combination of 2 losses during training:
1. reconstruction loss (e.g., difference between input and reconstructed pixels, like MSE or cross-entropy)
2. KL divergence between the approximate posterior q(z|x) (learned latent distribution) and the prior p(z) (Gaussian), which keeps the latent space close to the prior so that inference and sampling are easier.
U-Net

> residual conn between encoder and decoder, so it learnzzz intricacies better.
its a good model ser.
[todo, contemplating]
Diffusion babe
todo, contemplating